Autores
- Sergio Ivvan Valdez Peña, CONACYT-CentroGeo
- Zaira Martínez Vargas, Universidad de Guadalajara
- Jorge Paredes Tavares, CONACYT-CentroGeo
Resumen
El objetivo de este trabajo fue utilizar una red neuronal para poder predecir datos de precipitación a partir de datos conocidos y de las estaciones más cercanas utilizando una base de datos tomada de la página de CONAGUA del gobierno de México.
Introducción
El clima define las condiciones temporales meteorológicas que caracterizan un lugar determinado. Por esto, es un factor que influye de manera significativa en la sociedad. Existen seis componentes importantes del clima: la temperatura, la presión atmosférica, el viento, la humedad, la precipitación y la cantidad de nubes. Teniendo todas estas características es posible saber el tipo de clima que habrá en cualquier momento [1]. Por esta razón, se utilizan herramientas basadas en redes neuronales para predecir datos climatológicos y obtener mejores resultados. Las redes neuronales están formadas por un conjunto de nodos capaces de transferir información entre ellos de forma parecida a como lo hacen las neuronas del cerebro. Su entrenamiento se basa en el ajuste de dichas conexiones o de hiperparámetros que son métodos de aprendizaje [2]. Uno de los tipos de neuronas artificiales es el perceptrón desarrollado entre 1950 y 1960 por el científico Frank Rosenblatt. El perceptrón toma varias entradas de información y produce una única salida. Asimismo, una forma de pensar el perceptrón es como un dispositivo que toma decisiones basado en un peso dado a cada característica. Estas redes neuronales están compuestas de neuronas de entrada, neuronas de salida y capas ocultas, donde dependiendo de la cantidad de capas ocultas obtenemos un algoritmo más complicado.
Así pues, siendo el clima un importante campo de investigación en los últimos años, y siendo las redes neuronales la mejor técnica para encontrar las relaciones entre diversas entidades [3], en este trabajo se utiliza una red neuronal perceptrón para predecir datos de precipitación tomando información de 15 años registrados en las estaciones meteorológicas de México, utilizando los cinco vecinos más cercanos a cada estación para el entrenamiento de la red neuronal.
Metodología
Se tomaron datos del Servicio Meteorológico Nacional, específicamente, las normales climatológicas por estado de todo el país [4]. En cada estado había cinco tipos de archivos de los cuales se utilizaron los que se titulaban “PROYECTO BASES DE DATOS CLIMATOLÓGICOS” y “COMISIÓN NACIONAL DEL AGUA”. Primero, se hizo una limpieza de datos ya que estos estaban en formato de archivo de texto, es decir, no estaban en formato de tabla y no era posible trabajarlos. Después, se tomó la información de las estaciones: número de estación, nombre, latitud, longitud, altura y lugar de ubicación.
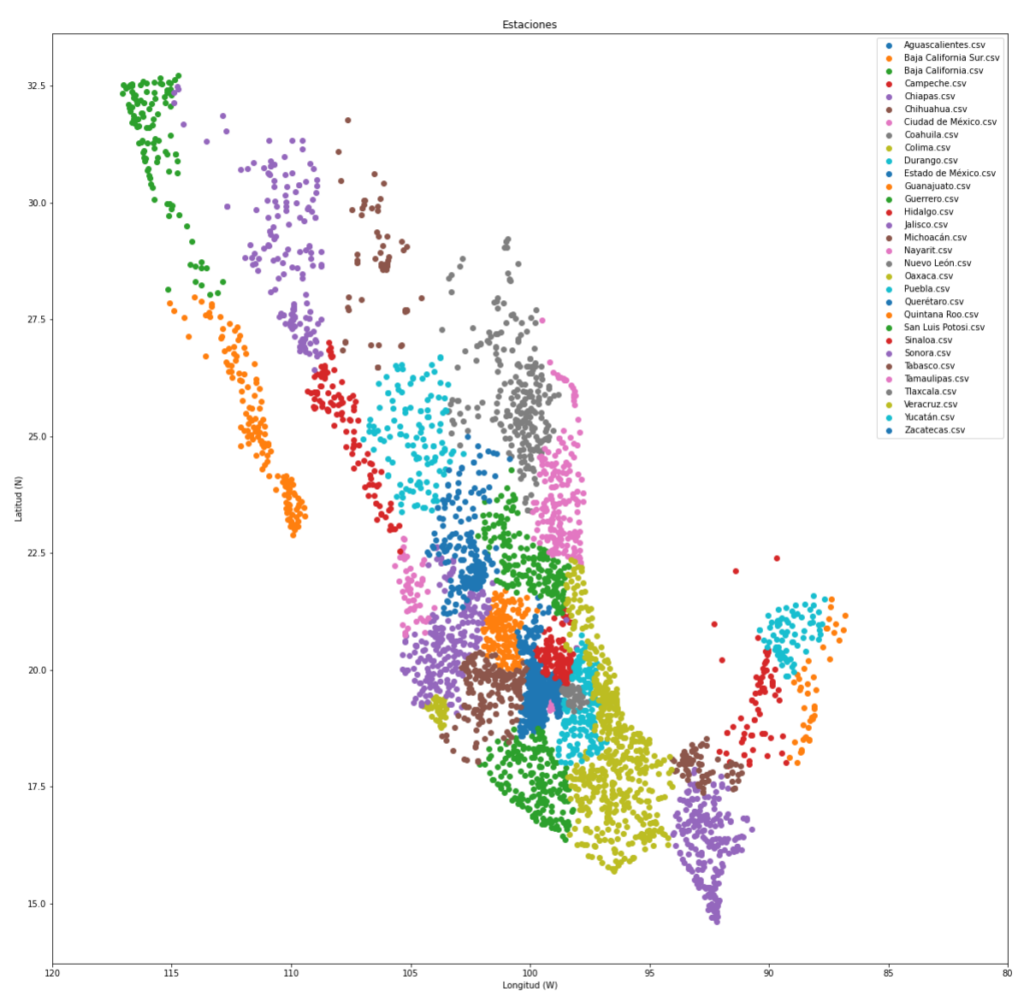
Con estos datos se encontraron las cinco estaciones más cercanas a cada estación, utilizando la fórmula haversine que determina la distancia de un círculo máximo entre dos puntos dados sus longitudes y latitudes (esto fue para observar si había correlación entre los datos de las estaciones vecinas). En la Figura 1 se muestran las estaciones de cada estado que se encontraron:
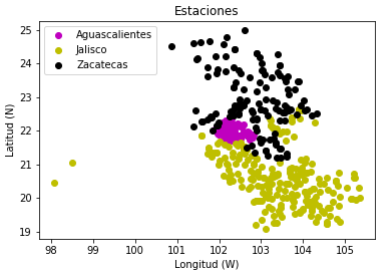
Sin embargo, dada la cantidad de información que había del país, el enfoque de este trabajo se hizo en Aguascalientes, por ello se analizaron los datos de Jalisco y Zacatecas por ser estados colindantes (Fig. 2).
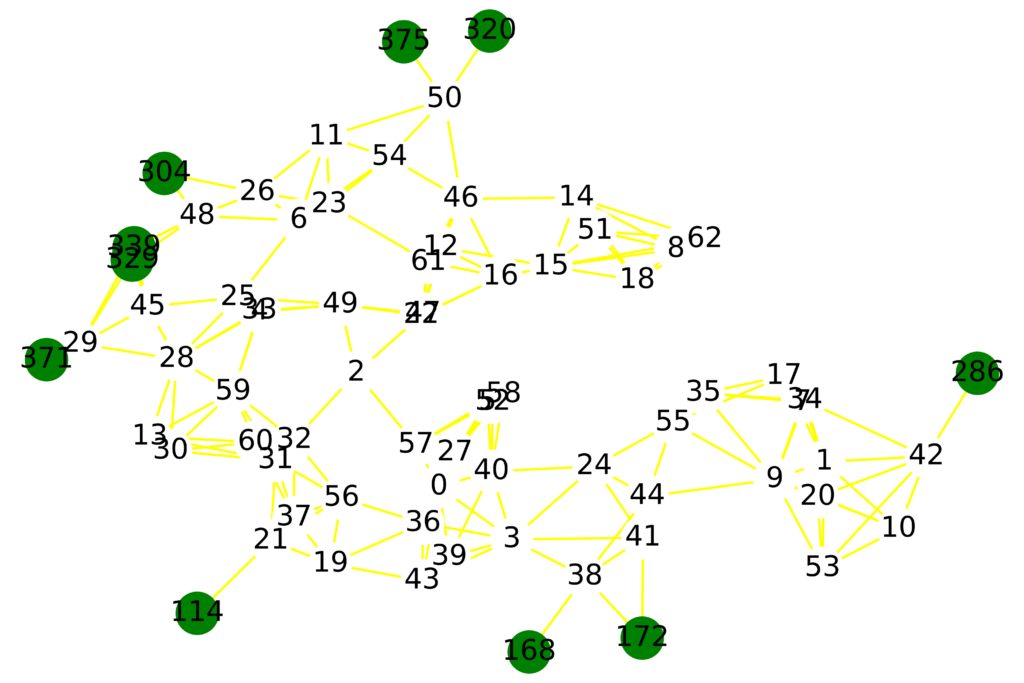
Asimismo, se obtuvo un grafo de los vecinos más cercanos (Fig. 3).
Al obtener los vecinos más cercanos, el siguiente paso fue encontrar la relación que había entre las estaciones. Por ello, se utilizó la información de los archivos que se titulaban ”COMISIÓN NACIONAL DEL AGUA”. La mayoría de los archivos contaban con once características: días con granizo, días con niebla, días con tormenta, evaporación mensual, lluvia máxima 24 horas, lluvia total mensual, temperatura máxima extrema, temperatura máxima promedio, temperatura media mensual, temperatura mínima extrema y temperatura mínima promedio.
No obstante, había archivos que no tenían datos de evaporación mensual, entre otros. Asimismo, cada característica tenía quince columnas de las cuales se tomaron 13: doce meses y el año al que pertenecían.
Ya que había datos que empezaban desde inicios del siglo XX hasta el XXI, se creó una base de datos donde estuvieran el año y mes (a partir del año 2002) y las estaciones como el Cuadro 1.
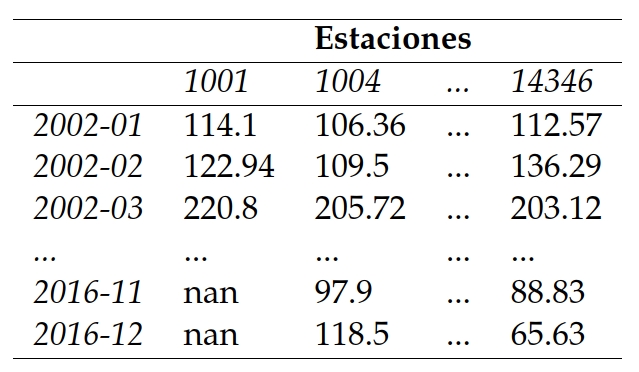
En este se puede observar que hay archivos nan estos son los que se buscó predecir y aunque no se muestre en la tabla, también había estaciones que no tenían ningún dato porque los datos de estas eran muy antiguos o no había datos de esta característica.
Se hicieron en total once tablas como la mostrada que incluía las estaciones de los tres estados ya mencionados, desde el año 2002 hasta el año 2017.
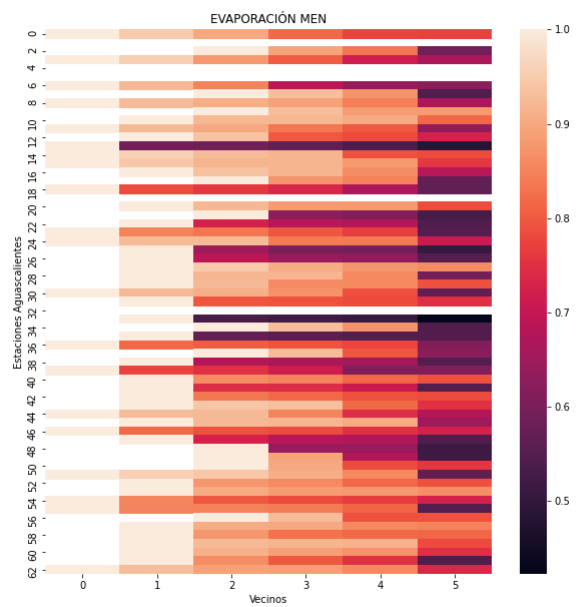
Al tener las bases de datos y los vecinos más cercanos, se hicieron matrices de correlación para cada característica (ver Fig.4 – Fig. 8) en estas se observan las 63 estaciones de Aguascalientes y la correlación con las cinco estaciones más cercanas donde el vecino cero es consigo misma.